
Qwen3.5をローカルで動かしてみた
はじめに
業務で活用する生成AI(LLM)は、ここ1〜2年で一気に選択肢が増えました。 ChatGPTやGemini、ClaudeといったAPI・Webツールを日常的に使っている人も多いと思いますが、今回紹介する Qwen 3.5 は、それらとは根本的に違うアプローチを取っています。
「トップクラスのAIを、自社の環境で動かす」というコンセプトのモデルで、手軽さよりも 機密性とカスタマイズ性 に重きを置いているのが特徴です。
この記事では、「Qwen 3.5」の実力と、 実際にPythonと連携させて「メールを自動でスプレッドシート化」 してみた結果をまとめていきます。
Qwen 3.5ってどんなモデル?
Qwenは、Alibaba Cloudが開発しているLLMシリーズです。その最新バージョンである「Qwen 3.5(2026年2〜3月リリース)」は、オープンモデル界隈で現在最も熱い注目を集めています。
最大のポイントは、 Apache 2.0ライセンスで商用利用が可能 であるという点です。実際にQwen3.5の9Bモデルが過去の100B級オープンモデルを凌駕するベンチマーク結果を出しており、この水準のAIを 自社サーバーで無料で動かせる専属AI として活用できるのがQwen 3.5の真価です。
※Apache 2.0ライセンス = 無償で商用利用が可能で、改変や再配布も自由度の高いオープンソースライセンスのこと
圧倒的な「日本語力」と「ネイティブマルチモーダル」
Qwen 3.5の大きな強みは以下の2点です。
アジア言語のニュアンス理解
最近の欧米発オープンモデル(Llama 3など)も多言語対応が大幅に改善されていますが、それでも 日本語特有の言い回し、敬語のニュアンス、ビジネスコンテキストの理解 においては、中国語等のアジア言語データを大量に学習しているQwenに一日の長があります。
※使用モデルによっては文字化けが起こったりはします。
ネイティブマルチモーダル(テキスト+画像+音声+動画)
Qwen 3.5の最大の進化点は、テキストだけでなく 画像や音声、動画までをネイティブに扱える ようになったことです(Qwen3.5-Omniシリーズ)。これにより、「PDFの請求書や添付画像を読み込ませて処理する」といった実務的なタスクを、ローカル環境で一挙にこなせるようになりました。
他のAPI型LLM(GeminiやClaude等)と何が違うのか
APIベースのモデルと比べた際の、Qwen 3.5の優位性は大きく分けて以下の4つです。
1. 「外部送信リスク」を排除できる
一般的なAPI型AIは、入力データを外部サーバーに送信します。Qwen 3.5は自社環境に直接デプロイできるため、顧客の個人情報や未公開の決算データなどを処理させても、 外部へのデータ送信に起因する情報漏洩リスクを排除できます (※社内でのログ管理やプロンプトインジェクション等、別のセキュリティ対策は別途必要です)。
2. 処理量に対する「追加API課金」がゼロ
中〜大規模なモデルを自社で動かすには、GPU(H100やA100など)の初期投資が必要であり、決して安くはありません。しかし、一度環境を構築してしまえば、 その後は何百万文字処理させてもランニングコストは電気代のみ です。使えば使うほどAPI課金が膨らむクラウド型モデルとは、コスト構造が根本的に異なります。
※H100やA100:データセンターなどで使われる、1枚数百万円するようなAI開発用の超高性能グラフィックボード
3. Thinking(推論)モードの実装
Qwen 3.5系の大きな特徴として、 「Thinking(推論)モード」と通常モードを切り替えられる 点が挙げられます。複雑な分類や論理的な情報抽出タスクにおいて、AIに「深く考えさせる」ことで回答精度を劇的に引き上げることが可能です。
4. 業務特化のファインチューニングが可能
API型のモデルは中身がブラックボックスですが、Qwen 3.5はオープンウェイトであるため、 自社の業務データを使った追加学習(ファインチューニング)や、マシンの性能に合わせたモデルの軽量化 といった技術的な調整が自由に行えます。特定の業務に特化させたAIを、自社だけの資産として持てるのは大きなメリットです。
受信メールをスプレッドシート化してみた
実際にQwenを使用して未読メールをデータ化してスプレッドシートに出力するパイプラインを作成してみました。
【検証環境スペック】
今回は手元のPCでどこまで動くかを検証するため、以下のスペックで実行しました。
- マシン: MacBook Pro
- チップ: Apple M2 Pro
- メモリ (RAM): 16GB
結果としては以下のようなメールを自分宛に送信して

実行すると以下のように出力されます。

今回は簡単に以下を出力しています。
- 件名
- 送信者
- 所属企業
- 要約
- 対応可否
Step 1: OllamaでQwen 3.5を召喚
まずはローカルLLM実行環境「Ollama」をインストールし、実務で最もバランスが良い7Bモデルを準備します(リソースに余裕があれば27B DenseやMoEモデルも選択可)。
ollama pull qwen3.5:7b
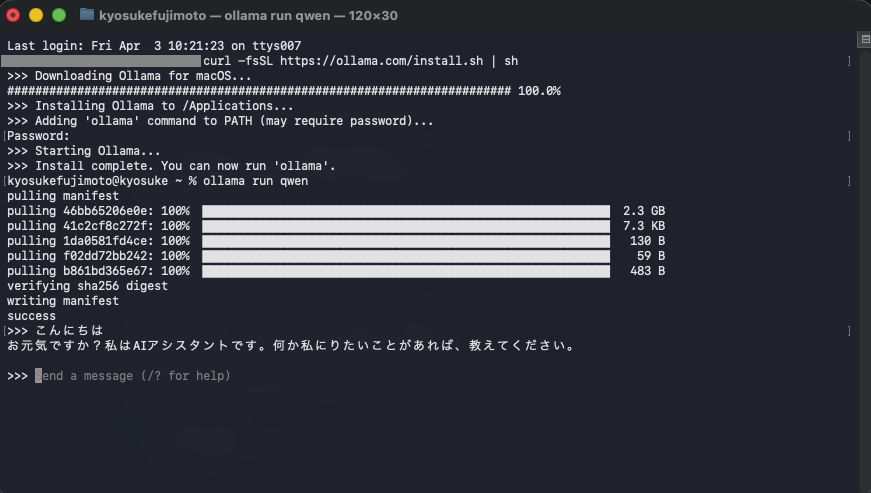
Step 2: メール取得
PythonでIMAPを使用して未読メールを抽出します。
Step 3: AIによる解析
取得した文面をローカルのQwen 3.5に投げ、JSON形式で情報を抽出させます。プロンプトの例:
""" 以下のメールを解析し、JSON形式で出力してください。 ※必ず日本語で出力すること。 項目:送信者名(sender_name)、所属企業(company)、要約(summary)、対応要否(action_required: true/false) """
Step 4: CSV(スプレッドシート)への書き出し
解析結果をCSV形式で保存します。
filename = f"email_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv" with open(filename, mode='w', encoding='utf-8-sig', newline='') as f: writer = csv.writer(f) writer.writerow(['件名', '送信者', '所属企業', '要約', '対応要否']) for item in results: ans = item["analysis"] writer.writerow([ item["original_subject"], ans.get("sender_name", ""), ans.get("company", ""), ans.get("summary", ""), ans.get("action_required", "") ])
実行結果
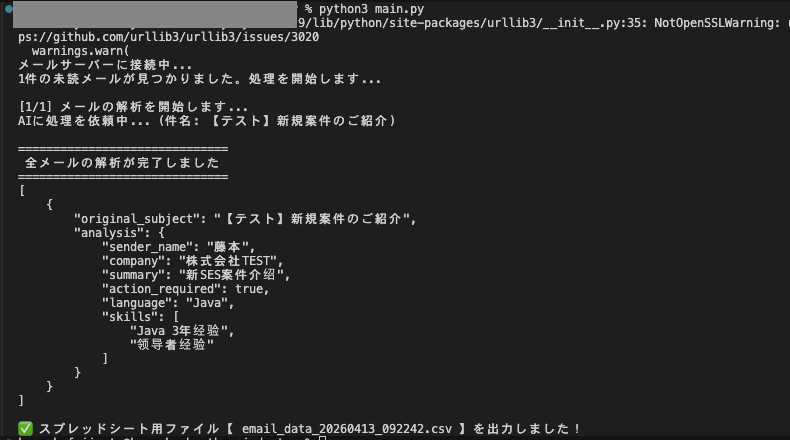
最終的にExcelやGoogleスプレッドシートで管理できる状態のCSVが自動で生成されます。
実際に動かした感想
嬉しいポイント
- 追加API課金ゼロの無限処理 — 新着メールや過去アーカイブを自動取得し、バックグラウンドのQwenにひたすら投げ続けます。初期投資の後は追加のAPI課金がゼロなので、「急がないから、マシンの空き時間を使って1週間かけて全部処理しておいて」といった贅沢な使い方が可能です。
- 機密情報の保護 — メールアドレスや顧客情報、添付の機密書類が社外に出ることはありません。外部送信に起因する情報漏洩リスクを排除した運用が実現します。
イマイチなポイント
- 軽量モデルでは日本語出力が不安定 — 今回使用した7Bモデルでは、要約タスクにおいて出力に中国語が混ざったり文字化けが発生するケースがありました。プロンプトで「日本語で出力すること」と強く指示しても完全には防げず、実運用ではバリデーションや再試行の仕組みを入れる必要があります。
- 精度を上げるにはハードウェア投資が必要 — この問題は27B Denseや35B-A3B MoEといった上位モデルに切り替えれば大幅に改善できますが、それにはVRAM 24GB〜48GB級のGPUや大容量メモリが必要です。 モデル精度とハードウェアコストのトレードオフ を、業務要件に合わせて見極める必要があります。
GPT-OSSと比較してみた
同じようにローカルLLMのGPT-OSSを使用して比較してみました。
今回使用したのはGPT-OSS-20Bです。
同じようにインストールをし、実行した結果以下のように表示されました。

[実行結果]
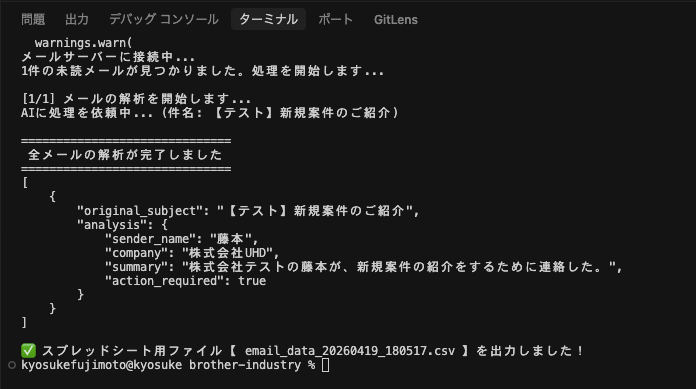
実行時間はQwenと比較して長くなりましたが、文字化けもせず綺麗に表示されました。
まとめ
Qwen 3.5は、「手軽にAIの答えを得たい」というより、「自社データを外に出さずに、業務システムへAIを組み込みたい」というニーズにフィットするモデルです。クラウドAIの手軽さとは別軸の価値を持っており、用途に応じて使い分けるのが現実的です。
今回の検証を通して、ローカルLLMを業務に組み込む際の 「モデル選びの重要性」 が明確になりました。
軽量で高速な「Qwen 3.5 (7B)」は処理スピードに優れるものの、複雑な抽出においては日本語の安定性に課題を残しました。一方で、少しサイズの大きい「GPT-OSS (20B)」に切り替えたところ、処理時間は長くなりましたが、文字化けや言語の混入がなくなり、実務に十分耐えうる完璧な精度のデータ抽出が実現できました。
クラウドAI(API型)の手軽さは魅力的ですが、本格的な業務自動化に進むと「ランニングコスト」と「機密情報のセキュリティ」が必ず壁になります。今回のように手元のPCや自社サーバーで環境を構築してしまえば、あとはセキュアかつ定額で大量のデータを処理し続ける自社専用のAIインフラを持つことができます。
「とにかく早く大量に処理したいなら7Bクラス」「時間がかかっても正確に読み解かせたいなら20Bクラス」といったように、業務要件とマシンスペックに合わせてAIの「脳」を自由に取り替えられるのも、ローカルLLMならではの最大の醍醐味です。
まずは手元のPCで実証実験(PoC)からスタートできますので、「この業務、ローカルAIで自動化できないか?」というアイデアがあれば、ぜひお気軽にご相談ください!
